KI Memory System: Welche Gedächtnisse ein KI-Agent wirklich braucht

Einleitung
Wer derzeit nach "Memory für KI-Agenten" sucht, findet zwanzig Frameworks, drei Vektordatenbanken und keinen klaren Plan. Jedes Tool verspricht das eine Gedächtnis, das alles löst. Spoiler: Das gibt es nicht.
Ein KI Memory System ist eine Architektur aus mehreren spezialisierten Gedächtnissen mit klar getrennten Aufgaben. Wer das versteht, kann Tools sinnvoll auswählen, statt jedem Trend hinterherzulaufen.
TL;DR
Memory in KI-Agenten ist ein Sammelbegriff für mindestens acht verschiedene Speichertypen. Wer ein Memory System für KI-Agenten baut, muss entscheiden, welche davon der Anwendungsfall braucht.
- Ein KI Memory System besteht aus mehreren Gedächtnisschichten mit getrennten Aufgaben
- RAG ist ein Zugriffsmuster, kein Memory-Typ. Ein LLM-Wiki ist kuratiertes Knowledge Memory und ergänzt RAG, statt es zu ersetzen
- Die zentrale Designfrage lautet: Welche Gedächtnisse braucht der Agent, und wie verzahnen sie sich
Was ist ein KI Memory System?
Ein KI Memory System ist die Gesamtheit aller Speicher- und Zugriffsmechanismen, die einen KI-Agenten über die aktuelle Session hinaus handlungsfähig machen. Es umfasst alles, was der Agent zwischen Anfragen behält oder bei Bedarf nachlädt.
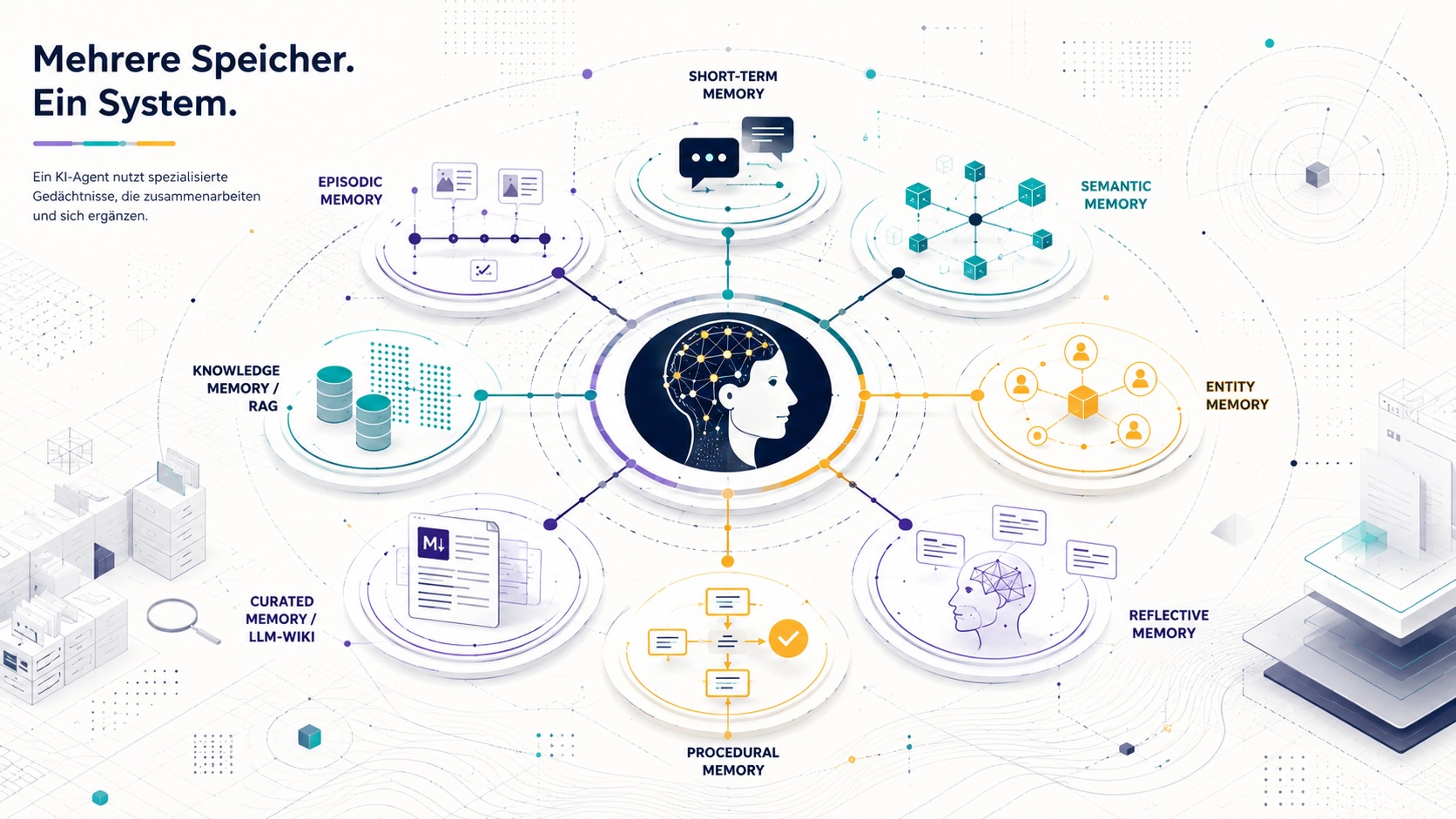
In der Diskussion tauchen verwandte Begriffe auf, die oft vermischt werden:
- Kontextmanagement für KI-Agenten beschäftigt sich damit, was im aktiven Kontextfenster steht.
- Kontextengineering für KI-Agenten plant, wie und woher dieser Kontext aufgebaut wird.
- Wissensmanagement für KI-Agenten regelt, welche externen Wissensquellen wie zugänglich sind.
Memory ist die Schicht darunter: die langlebige Speicherbasis, aus der Kontext und Wissen aktiviert werden.
Die acht Memory-Typen im Überblick
Ein nutzbares Memory System für KI-Agenten lässt sich in acht Typen zerlegen. Die Tabelle zeigt sie im Überblick.
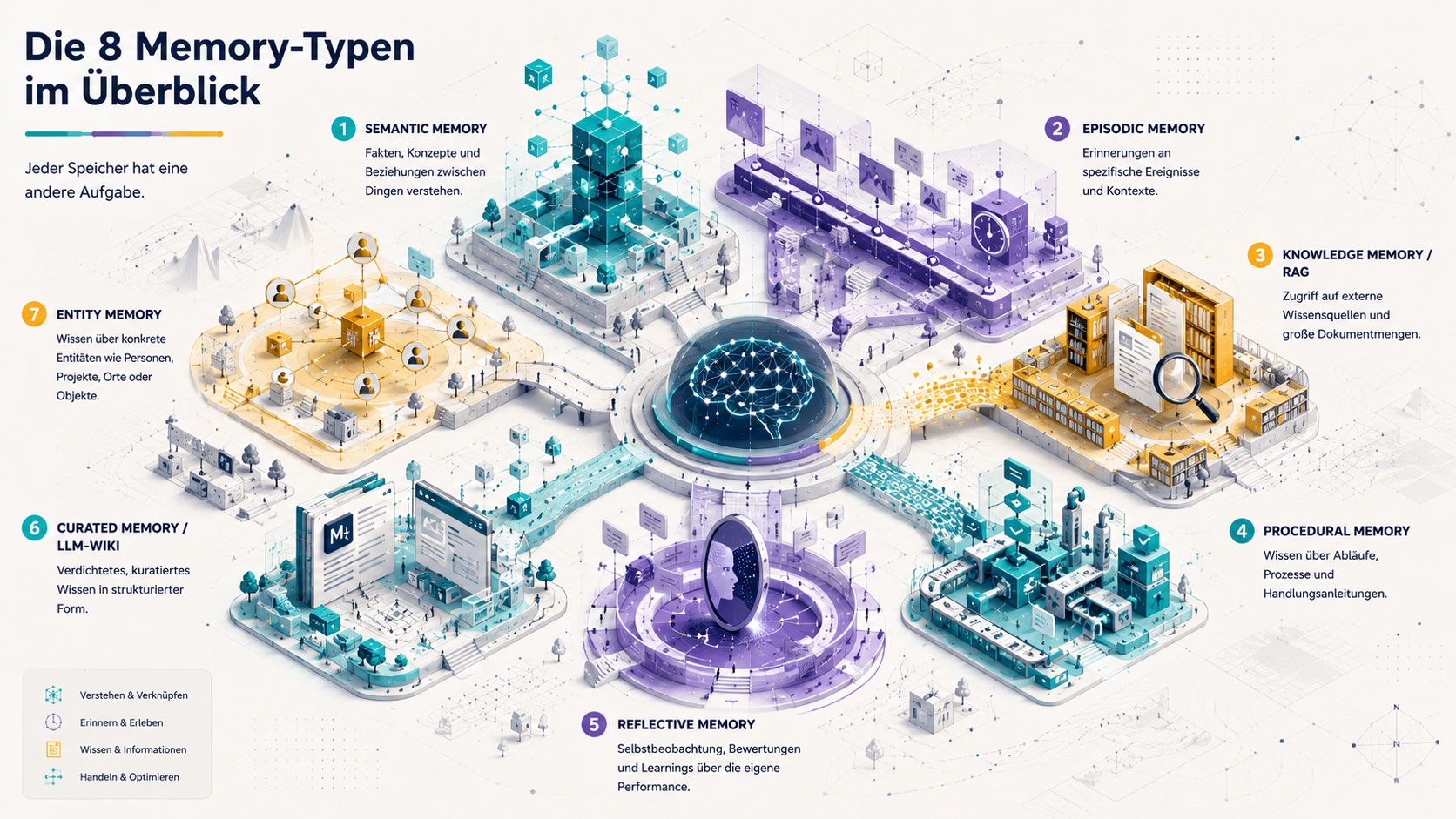
| Memory-Typ | Funktion | Beispiel |
|---|---|---|
| Short-Term Memory | Aktueller Gesprächskontext | Letzte Nachrichten im Chat |
| Semantic Memory | Stabile Fakten zu User und Regeln | "Erik schreibt auf Deutsch, bevorzugt klare Struktur" |
| Episodic Memory | Erinnerungen an vergangene Ereignisse | "Letzte Woche wurde Problem X so gelöst" |
| Procedural Memory | Wissen über Abläufe | "Blogposts: erst These, dann Struktur, dann Draft" |
| Knowledge Memory / RAG | Zugriff auf große Dokumentmengen | SharePoint, Confluence, PDFs |
| Curated Memory / LLM-Wiki | Verdichtetes, gepflegtes Themenwissen | Wiki für ein Marketing-Team |
| Entity Memory | Wissen über konkrete Personen, Projekte, Geräte | Kunde A, Projekt B, Server C |
| Reflective Memory | Vom Agenten erzeugte Learnings | "Bei solchen Aufgaben erst Quellen prüfen" |
Drei Punkte zur Tabelle, weil sie oft missverstanden werden. Erstens: Die Typen schließen sich nicht aus. Ein Agent kann Semantic Memory und Entity Memory parallel führen. Zweitens: Sie sind nicht gleich wichtig für jeden Anwendungsfall. Drittens: Die Übergänge sind fließend. Eine kuratierte Wiki-Seite kann gleichzeitig als Knowledge Memory und Entity Memory wirken.
Ist RAG ein Memory-Typ?
Kurze Antwort: Nein. RAG ist ein Zugriffsmuster.
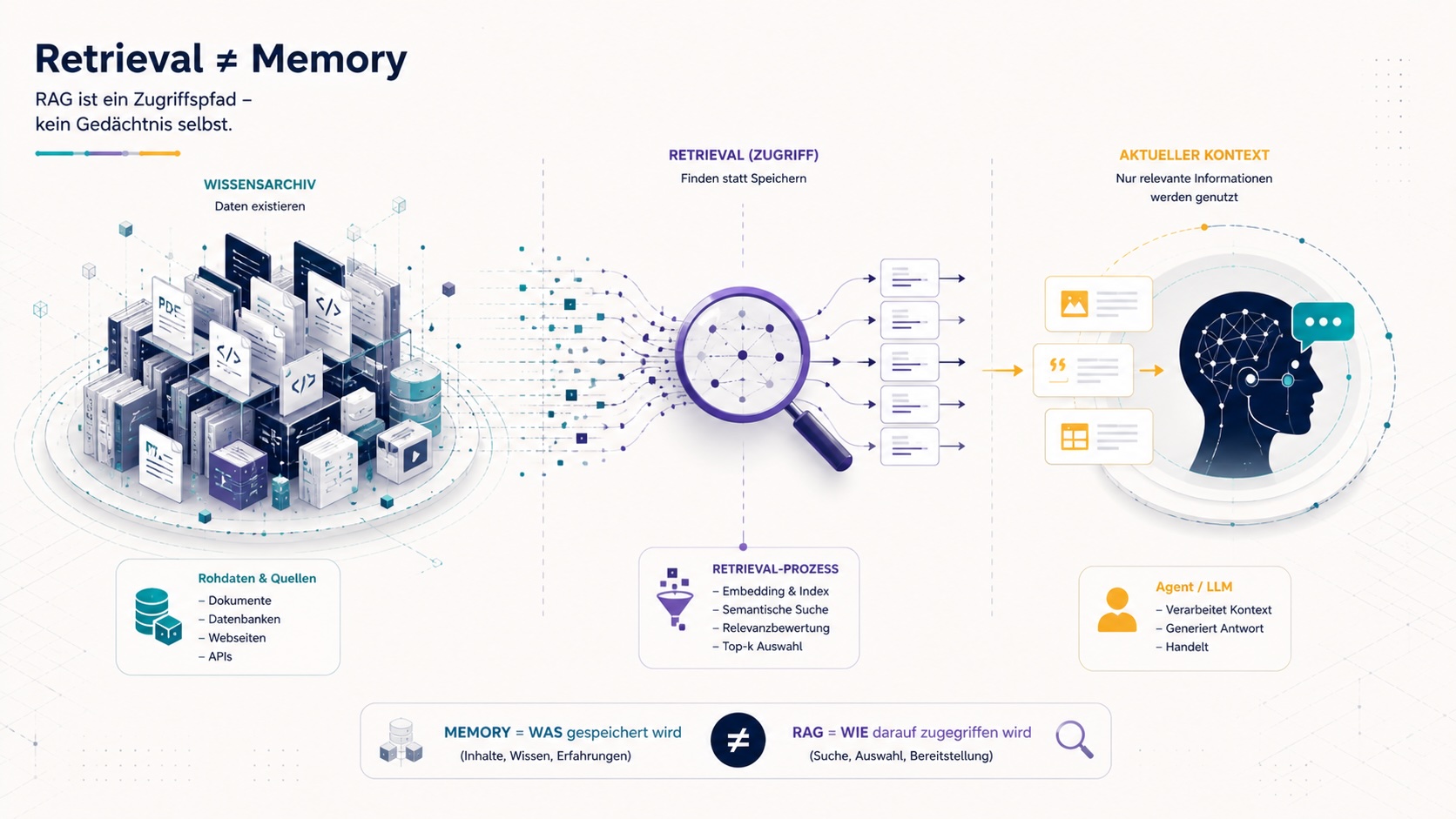
Genauer formuliert: RAG (Retrieval Augmented Generation) beantwortet die Frage, wie ein Agent relevante Informationen aus einem großen Speicher zurückholt. Memory beantwortet die Frage, was überhaupt gespeichert wird, wie es gepflegt wird und wann es relevant ist. Beide Themen hängen zusammen, fallen aber nicht zusammen.
Konsequenz für die Architektur: Ein LLM-Wiki kann selbst per RAG durchsucht werden. Eine Vektordatenbank ist Infrastruktur, in der Memory abgelegt sein kann. Wer "RAG vs Memory" diskutiert, vergleicht oft Äpfel mit Speisekarten.
LLM-Wiki: kuratiertes Wissensmanagement für KI-Agenten
Das LLM-Wiki ist eine Idee, die in der Memory-Debatte zunehmend auftaucht. Andrej Karpathy hat sie öffentlich beschrieben. Sie geht ungefähr so:
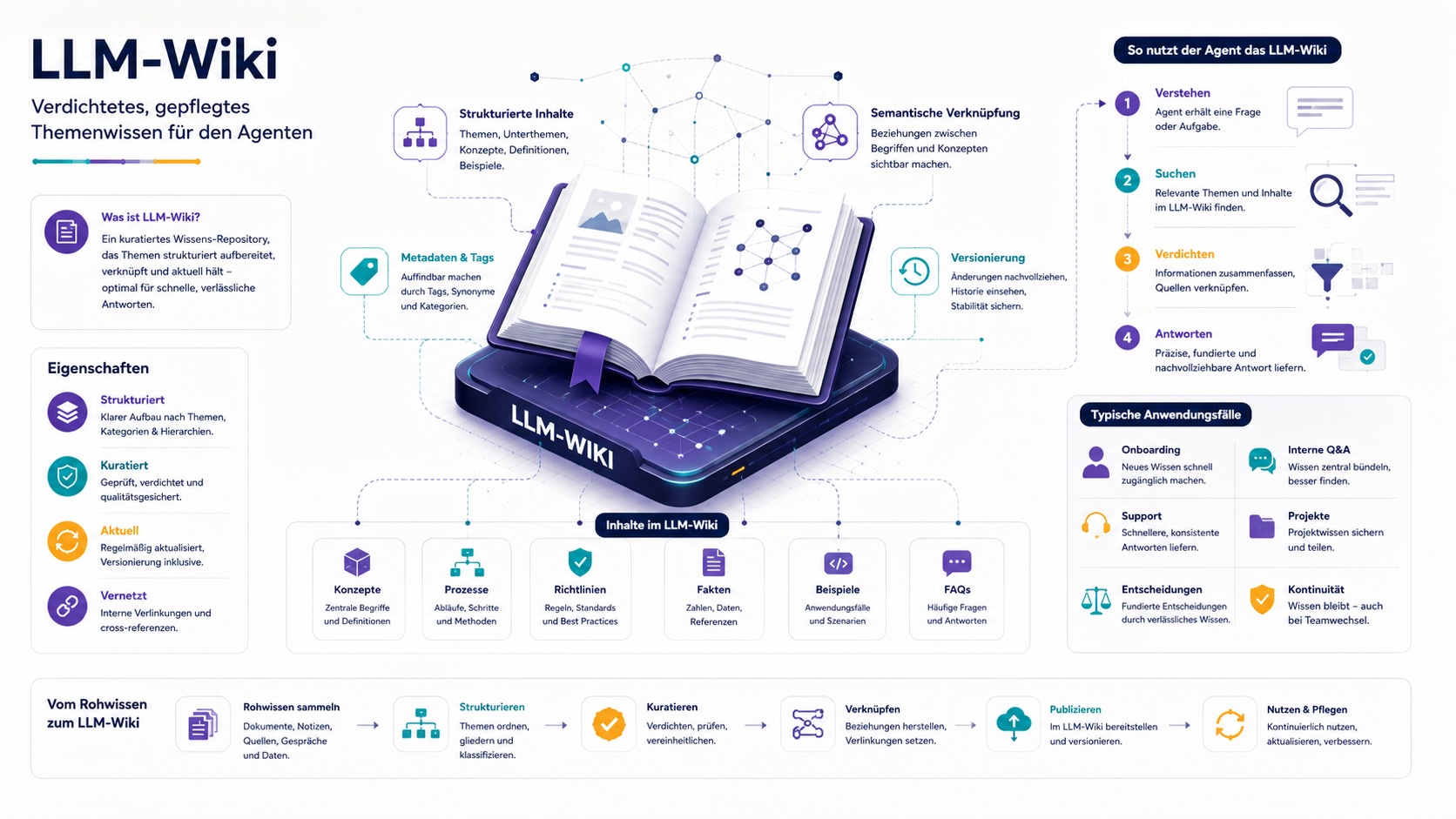
Statt bei jeder Frage neu aus Rohdokumenten Antworten zu erzeugen, baut der Agent eine zwischenliegende Wissensschicht auf. Diese Schicht besteht aus Markdown-Seiten, die das LLM selbst pflegt. Hinzu kommen die Rohquellen und eine Navigations- bzw. Schemaschicht.
Was das bringt:
- Wissen wird verdichtet, statt jedes Mal aus Rohtext rekonstruiert zu werden
- Antworten werden konsistenter, weil sie aus einer kuratierten Quelle kommen
- Fehler sind sichtbar, weil sie im Wiki stehen und nicht in einem flüchtigen Generierungsschritt entstehen
Die Einschränkung: Das funktioniert für abgegrenzte, stabile Themen. Bei Wissen, das sich täglich ändert oder zu groß ist, um verdichtet zu werden, bleibt klassisches RAG die bessere Wahl. Das LLM-Wiki kommt als zusätzliche Schicht hinzu.
Für ein KI Memory System bedeutet das: Curated Memory und Knowledge Memory sind zwei verschiedene Schichten mit unterschiedlichen Updatezyklen.
User- und Agent-Memory: das Beispiel Honcho
Honcho beschreibt sich als Memory-Library für stateful Agents. Im Fokus stehen Personen, Beziehungen und Verhalten. Honcho modelliert Entitäten wie User, Agents, Gruppen und ihre Eigenschaften über Zeit hinweg.
In Hermes wird Honcho als Memory-Backend genutzt. Statt einfacher Key-Value-Speicherung baut das System nach Gesprächen ein laufendes Modell des Users auf: Präferenzen, Ziele, Muster.
Das ist ein anderer Memory-Typ als RAG oder LLM-Wiki. Der Schwerpunkt liegt auf Semantic Memory und Entity Memory. Wer ein Memory System für KI-Agenten plant, sollte diese Trennung früh sauber führen, sonst entstehen Tools, die zu viel auf einmal versuchen und keines davon richtig.
Welche Memorys braucht ein KI Memory System wirklich?
Die Antwort hängt vom Anwendungsfall ab. Drei Stufen helfen bei der Einordnung.
Minimum für jeden Agenten
- Short-Term Memory, sonst kein Gesprächsverlauf
- Semantic User Memory für stabile Präferenzen, Sprache und Ton
- Projekt- oder Entity-Memory für kontextspezifisches Wissen
Zusätzlich für Wissensarbeit
- RAG auf große Quellen
- LLM-Wiki für kuratierte Themen
- Quellenverweise und Provenance, damit Antworten überprüfbar bleiben
Zusätzlich für autonome Agenten
- Episodic Memory: was wurde wann gemacht
- Procedural Memory: wie wird etwas gemacht
- Reflection Loops: der Agent zieht Schlüsse aus eigenem Verhalten
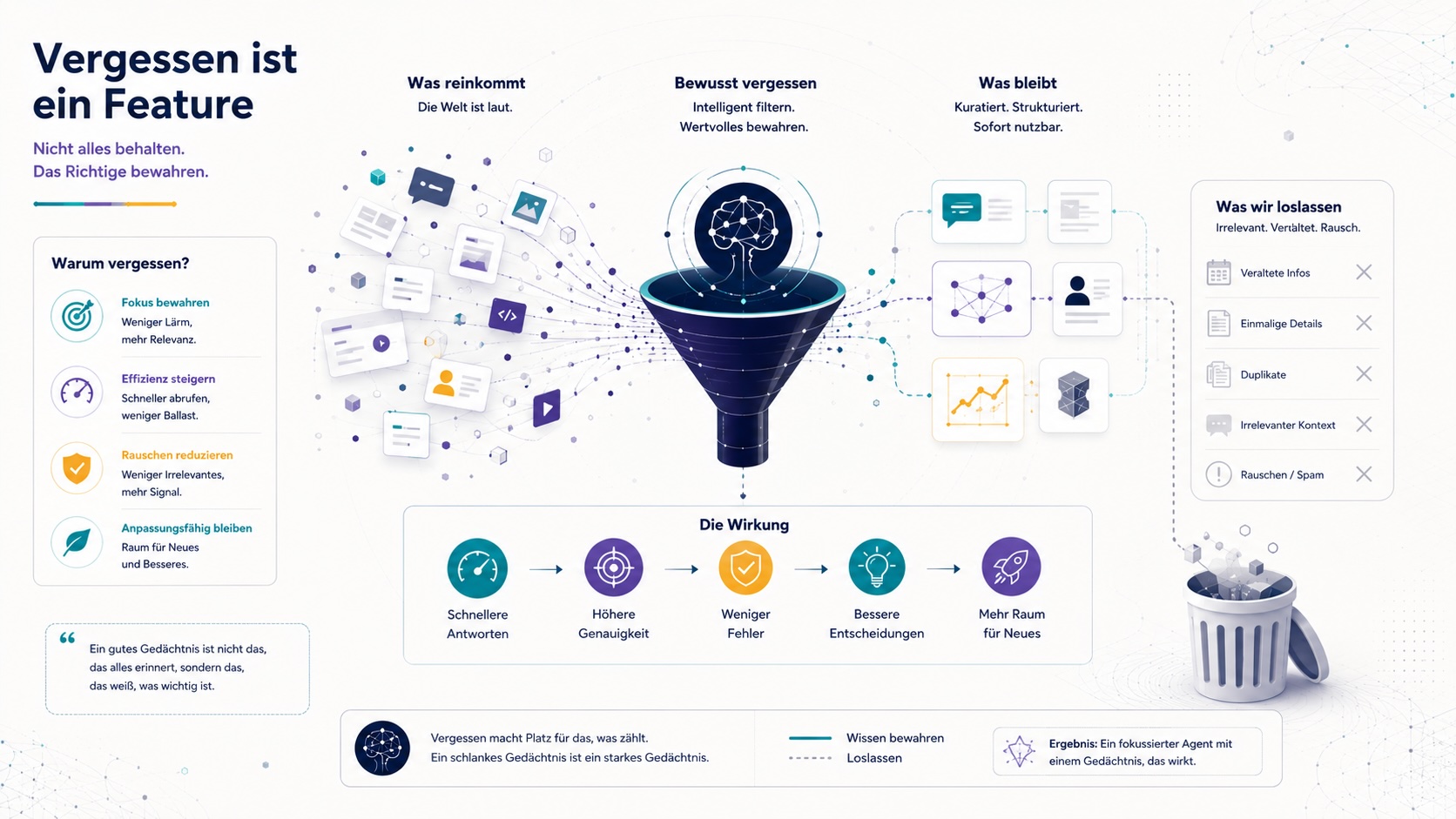
- Memory Decay: ein Mechanismus zum Vergessen, sonst wächst der Speicher unkontrolliert
Die Stufen sind kumulativ. Ein autonomer Agent ohne Semantic User Memory ist genauso unbrauchbar wie einer ohne Reflection Loops.
Zielkonflikte beim Memory-Design
Jede Memory-Entscheidung kostet etwas. Die folgende Tabelle zeigt die wichtigsten Spannungsfelder.
| Ziel | Problem |
|---|---|
| Alles speichern | Speicher wird chaotisch und teuer |
| Nur Wichtiges speichern | Agent entscheidet eventuell falsch, was wichtig ist |
| Wissen verdichten | Fehler in der Verdichtung schleichen sich dauerhaft ein |
| Rohquellen behalten | Antworten werden langsamer und teurer |
| Agent kuratiert selbst | Governance wird schwierig, Audit fast unmöglich |
| Mensch kuratiert alles | Skaliert schlecht, wird zum Engpass |
Diese Konflikte lassen sich nicht auflösen, nur austarieren. Die Auswahl der Memory-Typen ist im Kern eine Entscheidung darüber, welche dieser Risiken man eingeht.
Häufige Fehler / wichtige Hinweise
- Ein Tool für alles wählen. Vektordatenbanken sind Infrastruktur. Wer eine installiert und das Memory-Thema abhakt, hat Knowledge Memory ohne Semantic, Entity oder Procedural Memory.
- Memory mit Logging verwechseln. Ein Archiv aller Gespräche ist noch kein Memory System. Ohne Strukturierung, Verdichtung und Zugriffsmuster bleibt es ein durchsuchbarer Logfile.
- Reflection Loops ohne Governance. Wenn der Agent eigene Learnings ableitet, ohne Review-Mechanismus, driftet das System unkontrolliert.
- Kein Memory Decay. Speicher, der nur wächst, wird zur Last. Vergessen ist ein Feature, kein Bug.
- Quellenverweise weglassen. Ohne Provenance wird Wissensmanagement für KI-Agenten in Unternehmenskontexten praktisch unbrauchbar.
FAQ
Was ist der Unterschied zwischen Kontextmanagement und Memory?
Kontextmanagement betrifft den aktiven Kontext, der gerade an das Modell geht. Memory ist die langlebige Schicht darunter, aus der Kontext aufgebaut wird. Kontextengineering für KI-Agenten ist die Disziplin, beides sinnvoll zu verbinden.
Brauche ich für meinen Agenten wirklich acht Memory-Typen?
Nein. Für die meisten Agenten reichen drei bis vier. Die acht Typen sind ein Analyse-Raster, keine Einkaufsliste.
Ist ein LLM-Wiki besser als RAG?
Beides hat einen anderen Zweck. RAG eignet sich für große, sich ändernde Quellen. Ein LLM-Wiki eignet sich für abgegrenzte Themen mit hohem Konsistenzbedarf. Reife Memory-Systeme nutzen oft beides parallel.
Wie speichere ich Memory technisch?
Vektordatenbanken für Knowledge Memory, strukturierte Stores oder Graphdatenbanken für Entity und Semantic Memory, einfache Markdown- oder JSON-Files für Procedural und Curated Memory. Der Tech-Stack ergibt sich aus der Funktion des Memory-Typs.
Was passiert, wenn ich kein Memory System habe?
Der Agent verhält sich in jeder Session wie beim ersten Mal. Für einfache Tools reicht das. Für alles, was über mehrere Interaktionen oder Aufgaben läuft, wird der fehlende Speicher schnell zum Hauptproblem.
Fazit
Ein KI Memory System ist immer mehrere Gedächtnisse mit klar getrennten Aufgaben. Wer ein Memory System für KI-Agenten plant, sollte zuerst klären, welche der acht Typen der Anwendungsfall braucht, und dann Tools auswählen, statt umgekehrt vorzugehen.
Die zentrale Frage lautet: Welche Schichten braucht mein Agent, und wie sehen Updatezyklen, Governance und Vergessen aus? Wer diese Frage früh beantwortet, baut ein System, das mit dem Anwendungsfall mitwachsen kann.
Hilfreiche Links
- Andrej Karpathy: LLM-Wiki Konzept (Gist)
- LangChain: Memory for Agents
- Serokell: Design Patterns for Long-Term Memory in LLM-Powered Architectures
Autor: Erik Weber